¿Qué es Pipeline?
¿Qué es Pipeline?¶
Si te preguntaran cómo construir una aplicación, lo más probable sería que empieces con la toma de requisitos. De esta forma, descomponerías el problema en varios subproblemas. Luego, irías resolviendo cada subproblema paso a paso para llegar así al tan deseado despliegue de tu aplicación. En el contexto de los modelos que involucren el procesamiento del lenguaje también ocurre esto.
Un pipeline de NLP no es más que la serie de pasos involucrados para construir cualquier modelo de NLP.
Estos pasos comunmente están en todos los proyectos de NLP, así que tiene sentido estudiarlos. Entender estos procedimientos nos permitirá adentrarnos a la resolución de cualquier problema de NLP.
Hoy en día, los componentes principales de un pipeline genérico para el desarrollo de sistemas NLP son los siguientes:
Adquisición de datos
Limpieza de texto
Preprocesamiento
Extracción de características o Feature Engineering
Modelamiento
Evaluación
Despliegue
Monitoreo y actualización del modelo
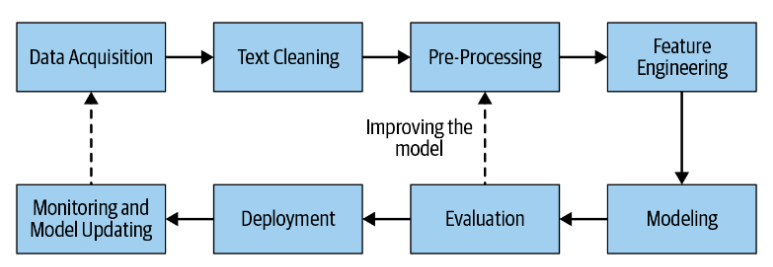
El primer paso en el proceso de desarrollo de cualquier sistema NLP es recolectar la información relevante para cierta tarea. Aunque se estuviera construyendo un sistema basado en reglas, igual necesitaríamos algunos datos para diseñar y testear nuestras reglas. Estos datos que obtenemos rara vez están limpios, aquí es donde la limpieza de texto entra en juego. Luego de la limpieza, los datos de texto suelen presentar ciertas variaciones y para trabajar con ellos es necesario convertirlos en su forma canónica. Esto es hecho en la etapa de preprocesamiento, seguido por la etapa de extracción de características donde tallamos los indicadores que son más adecuados para la tarea en cuestión. Estos indicadores se convierten a un formato comprensible mediante algoritmos de modelado. Luego viene la fase de modelado y evaluación, donde construimos uno o más modelos y los comparamos y contrastamos utilizando métricas de evaluación relevantes. Una vez elegido el mejor modelo entre los evaluados, avanzamos hacia el despliegue de este modelo en producción. Por último, supervisamos periódicamente el rendimiento del modelo y, si es necesario, lo actualizamos para mantener su rendimiento.
Tenga en cuenta que, en el mundo real, es posible que el proceso no siempre sea lineal, como se muestra en el pipeline de la figura; a menudo implica ir y venir entre pasos individuales (por ejemplo, entre extracción de características y modelado, modelado y evaluación, etc.). Además, hay bucles intermedios que normalmente van desde la evaluación hasta el preprocesamiento, extracción de características, el modelado y de regreso a la evaluación. Este también es un ciclo general que va desde el monitoreo hasta la adquisición de datos, pero este ciclo ocurre a nivel de proyecto.
También tenga en cuenta que los procedimientos exactos paso a paso pueden depender de la tarea específica en cuestión. Por ejemplo, un sistema de clasificación de texto puede requerir un paso de extracción de características diferente en comparación con un sistema de resumen de texto. Además, dependiendo de la fase del proyecto, diferentes pasos pueden tomar diferentes cantidades de tiempo. En las fases iniciales, la mayoría del tiempo es usado en el modelamiento y evaluación, mientras que cuando ya se cuenta con un modelo robusto la extracción de características puede tomarnos más tiempo.