Machine learning, Deep Learning y NLP
Contenido
Machine learning, Deep Learning y NLP¶
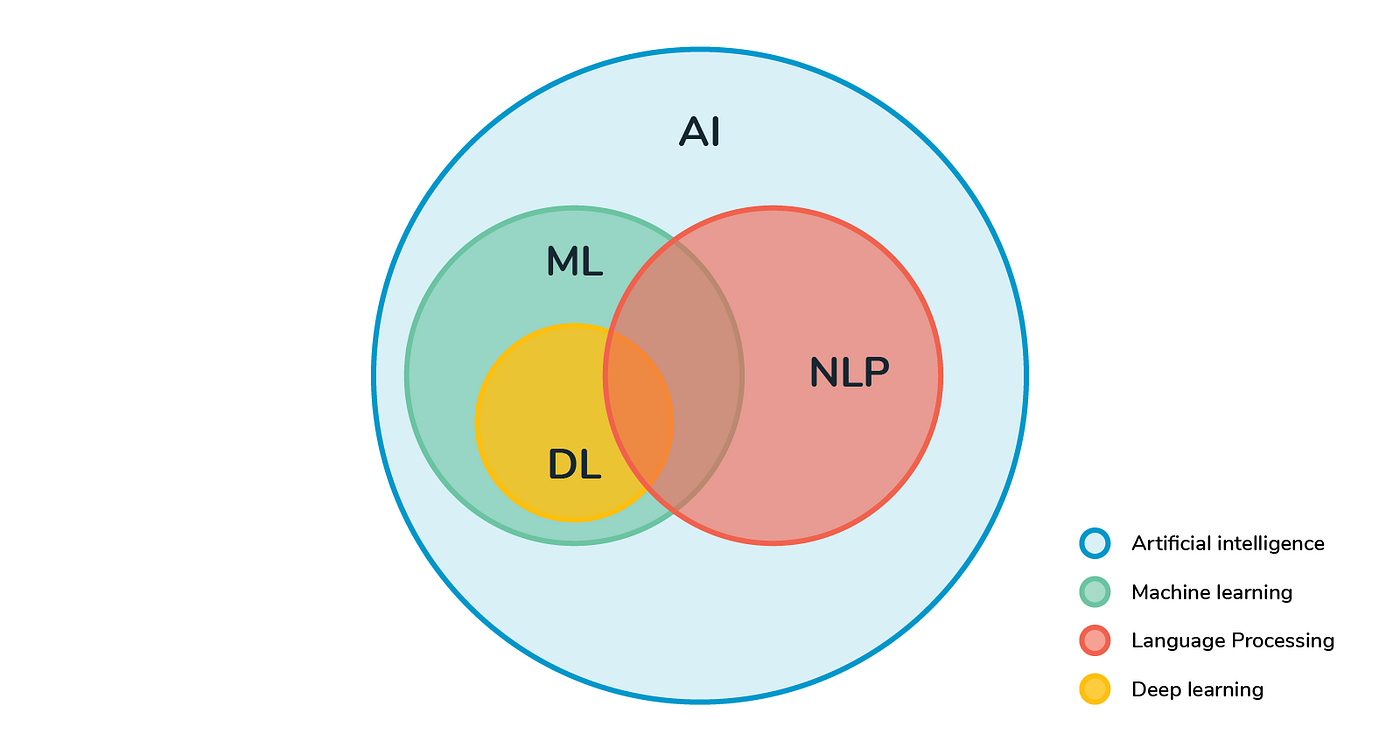
La inteligencia artificial (AI) es una rama de las ciencias de la computación cuyo objetivo es construir sistemas que puedan desarrollar tareas que requieran de la inteligencia humana.
Machine learning (ML o aprendizaje de máquina) es una rama de la inteligencia artificial cuyo objetivo es desarrollar algoritmos que pueden aprender a desarrollar tareas de forma automática, basándose en un gran número de ejemplos.
Deep Learning (DL o aprendizaje profundo) es una rama de machine learning basada en arquitecturas de redes neuronales artificiales
NLP, ML y DL pueden traslaparse, sin embargo, son áreas de estudio diferentes.
Al igual que en la inteligencia artificial, los primeros avances de NLP eran basados en reglas y heurísticas. Luego, con el paso de los años y los grandes avances en ML y DL, NLP fue adquiriendo parte de sus técnicas, modelos y arquitecturas.
El objetivo del machine learning es “aprender” a desarrollar tareas basándose en ejemplos (llamados “datos de entrenamiento”) sin instrucciones explícitas. Esto típicamente se realiza creando una representación numérica de los datos de entrenamiento y usando dicha representación para aprender los patrones implícitos.
Los algoritmos de machine learning se pueden agrupar en tres paradigmas: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje por reforzamiento.
En el aprendizaje supervisado, el objetivo es aprender la función de mapeo de entrada a salida dada una gran cantidad de ejemplos en forma de pares de entrada-salida. Los pares de entrada-salida se conocen como datos de entrenamiento y las salidas se conocen específicamente como etiquetas. Un ejemplo de un problema de aprendizaje supervisado relacionado con el lenguaje es aprender a clasificar los correos electrónicos como spam o no spam dado miles de ejemplos en ambas categorías. Este es un escenario común en NLP.
El aprendizaje no supervisado se refiere a un conjunto de métodos de machine learning que tienen como objetivo encontrar patrones ocultos en los datos de entrada sin ninguna salida de referencia. Es decir, en contraste con el aprendizaje supervisado, el aprendizaje no supervisado funciona con grandes colecciones de datos no etiquetados. En NLP, un ejemplo de tal tarea es identificar temas latentes en una gran colección de datos textuales sin ningún conocimiento de estos temas. Esto se conoce como topic modeling (modelado de temas).
El aprendizaje por reforzamiento se ocupa de métodos para aprender tareas a través de prueba y error. Se caracteriza por la ausencia de datos etiquetados o no-etiquetados en grandes cantidades. El aprendizaje se realiza en un entorno autónomo y mejora a través de la retroalimentación (recompensa y castigo) facilitada por el entorno. Esta forma de aprendizaje no es común en la NLP (todavía). Es más común en aplicaciones como juegos (go, ajedrez, etc), en el diseño de vehículos autónomos y en la robótica.
Enfoques de NLP¶
Los diferentes acercamientos usados para resolver problemas de NLP comúnmente caen en tres categorías: heurísticas, machine learning y deep learning.
1. basado en heurísticas¶
Similar a los primeros sistemas de inteligencia artificial, los primeros intentos para diseñar sistemas de NLP estuvieron basados en la construcción a mano de reglas para resolver problemas del lenguaje. Esto requeria que los desarrolladores tuvieran cierta expertiz en el dominio para formular reglas que pudieran ser incorporadas en un programa. Estos sistemas requerian recursos como diccionarios y tesauros (de forma simplificada, un tesauro es una especie de diccionario que linkea la palabra de interés con sus sinónimos), típicamente compilados y digitalizados a través de ciertos periodos de tiempo. Un ejemplo de diseñar reglas para resolver un problema de NLP usando recursos es el “lexicon-based sentiment analysis” (o análisis de sentimientos basado en léxico). Utiliza contadores de palabras positivas y negativas en el texto para deducir el sentimiento del texto.
Las expresiones regulares (regex) son una buena herramienta para el análisis de textos y para la construcción de sistemas basados en reglas. Una expresión regular es un conjunto de caracteres o un patrón que se usa para encontrar substrings en el texto. Además son usadas para matches o coincidencias determinísticas -vale decir, es una coincidencia o no lo es. Las expresiones regulares probabilísticas son una rama secundaria que aborda esta limitanción al incluir una probabilidad de coincidencia.
La gramática de libre contexto (Context-free grammar o CFG) es un tipo de gramática formal que es usado para modelar lenguajes naturales. CFG fue inventada por Noam Chomsky y permite capturar información más compleja y jerárquica, en situaciones donde posiblemente las expresiones regulares serían una herramienta incompatible.
Las reglas y heurísticas juegan un rol importante en el ciclo de vida de los proyectos de NLP. Son una excelente forma de empezar a construir las primeras versiones de nuestros sistemas. Con tan solo un par de reglas y heurísticas puedes construir un modelo simple que te permitirá entender de mejor forma el problema.
2. basado en Machine Learning¶
Las técnicas de machine learning, como los métodos de clasificación y regresión, se utilizan mucho para diversas tareas de NLP. Como ejemplo, es posible clasificar un abanico de noticias en distintas categorias como economía, deportes o política. Por otro lado, las técnicas de regresión pueden entregarnos valores estimados a partir de un análisis de sentimientos de un activo en redes sociales.
Cualquier acercamiento de machine learning a NLP, supervisado o no supervisado, puede ser descrito consistentemente en tres pasos comunes:
extraer características del texto.
usar la representacipon de características para que el modelo pueda aprender
evaluar y mejorar el modelo.
- Naive Bayes¶
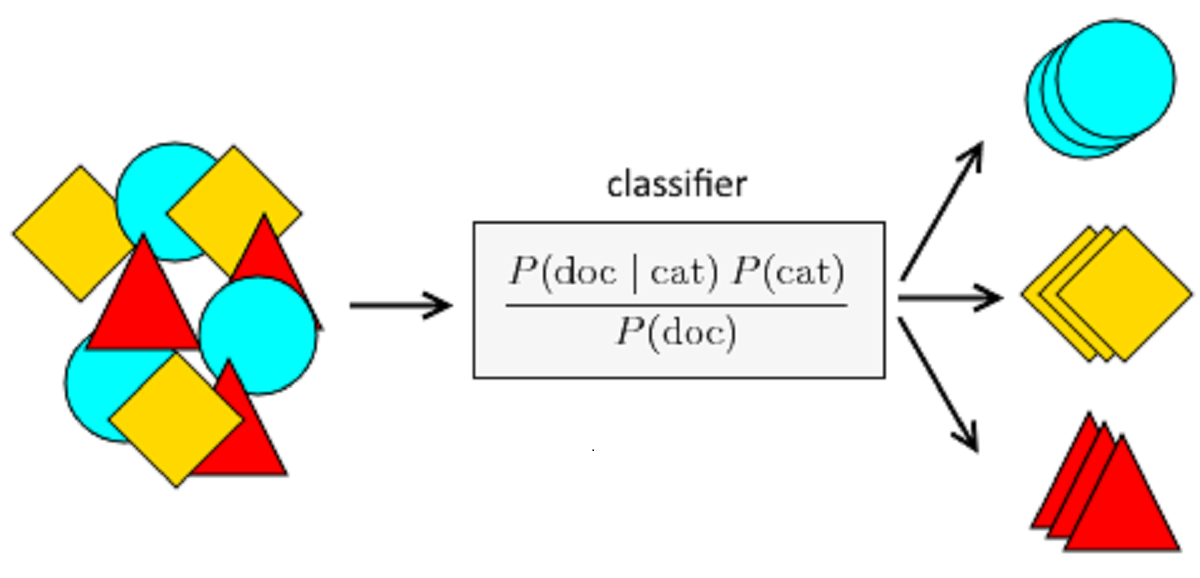
Naive Bayes es un algoritmo clásico para las tareas de clasificación que principalmente se basa en el teorema de bayes.
Usando el teorema de bayes se calcula la probabilidad de observar una categoría dado cierto input y las características de los datos. Una particularidad de este algoritmo es que asume que cada característica es independiente de las demás categorías. Por ejemplo, un modelo naive bayes clasificador de noticias puede representar el texto de forma numérica usando un contador de palabras clave por clase, palabras que son específicas para la clase deportes, política, arte, etc. y que están presentes en el texto. Se asume que estos contadores de palabras no están correlacionados con las demás categorías, y aunque esta asumpción es bastante fuerte, en algunos casos (poco probables) puede arrojar falsos positivos.
- Support Vector Machine (SVM)¶
Support Vector Machine es otro algoritmo de clasificación popular. El objetivo en cualquier técnica de clasificación es aprender los límites que actúan como separadores entre las distintas clases o categorías de texto (por ejemplo, política versus deportes, en nuestro ejemplo de clasificación de noticias). Estos límites de decisión pueden ser lineales o no lineales. SVM puede aprender límites de decisión lineales o no lineales para separar los datos pertenecientes a las distintas clases.
Una SVM puede aprender un límite de decisión óptimo para que la distancia entre los puntos de las clases sea máxima. La mayor fortaleza de las SVM es su solidez a la variación y el ruido en los datos. Una debilidad importante es el tiempo que se tarda en entrenar y la incapacidad de escalar cuando hay grandes cantidades de datos de entrenamiento.


- Conditional Random Fields (CRF)¶
Conditional random field (campo aleatorio condicional o CRF) es otro algorimo usado para datos secuenciales. Conceptualmente, CRF realiza una tarea de clasificación en cada elemento de la secuencia. Imagina el mismo ejemplo de POS tagging, donde un CRF puede etiquetar palabra por palabra clasificándolas en una clase del grupo de todos los tags de POS.
Dado que tiene en cuenta el input secuencial y el contexto de los tags, se vuelve más expresivo que los métodos de clasificación habituales y, en general, funciona mejor. Los CRF superan a los HMM en tareas como el POS tagging, que se basan en la naturaleza secuencial del lenguaje.
3. basado en Deep Learning¶
En los últimos años, se ha visto un surgimiento incrementado en el uso de redes neuronales que tratan con datos complejos y no estructurados. El lenguaje es inherentemente complejo y no estructurado. De esta forma, es necesario de modelos con mejores representaciones y capacidad de aprendizaje para entender y resolver tareas del lenguaje.
Las siguientes son las arquitecturas de redes neuronales profundas que se han vuelto el status quo en NLP.
- Recurrent Neural Networks (RNN)¶
El lenguaje es inherentemente secuencial. Una oración en cualquier lenguaje fluye desde una dirección a otra (por ejemplo, en inglés o español se lee desde izquierda a derecha). Por lo tanto, un modelo que pueda leer progresivamente un input de texto desde un extremo a otro puede ser muy útil para el entendimiento del lenguaje. Las redes neuronales recurrentes (RNNs) están especialmente diseñadas para mantener este procesamiento secuencial y aprendizaje en mente. RNNs tienen unidades neuronales que son capaces de recordar lo que han procesado hasta ahora. Esta memoria es temporal, y la información es almacenada y actualizada con cada paso mientras RNN lee la siguiente palabra del input.
La siguiente imagen ilustra una RNN desenrollada y como esta sigue la pista de sus inputs en distintos momentos.

Las RNN son muy poderosas y trabajan muy bien resolviendo problemas de NLP, como la clasificación de texto, reconocimiento de entidades nombradas (named entity recognition o NER), traducción automática, etc. También es posible generar texto con RNNs donde el objetivo es leer el texto que precede y predecir la palabra siguiente o el siguiente caracter.
- Long short-term memory (LSTM)¶
A pesar de su capacidad y versatilidad, RNNs sufren el problema de la “pérdida de memoria”, estas no pueden recordar largos contextos, y por lo tanto, no son eficientes cuando el input es grande, situación que típicamente es el caso con los inputs de texto. Long short-term memory networks (LSTMs), un tipo de RNN, fueron inventadas para mitigar este defecto de las RNNs.
LSTM sortea este problema dejando de lado el contexto irrelevante y recordando solo la parte del contexto que se necesita para resolver la tarea en cuestión. Esto alivia la carga de recordar un contexto muy largo en una representación vectorial. Los LSTM han reemplazado a los RNN en la mayoría de las aplicaciones debido a esta solución.
La siguiente figura ilustra la arquitectura de una sola celda LSTM.

- Convolutional neural networks¶
Las redes neuronales convolucionales (CNNs) son bastante populares y altamente usadas en tareas de visión computacional como clasificación de imágenes, reconocimiento de video, etc. Además, las CNNs hay sido bastante exitosas en NLP, especialmente en las tareas de clasificación de texto. Uno puede reemplazar cada palabra de una oración en una representación vectorizada de la misma, donde todos y cada uno los vectores son del mismo tamaño (Word Embeddings).
Además, estos vectores pueden ser apilados uno sobre otro para formar una matriz o un arreglo en 2D de dimensiones n x d, donde n es el número de palabras en una oración y d es el tamaño de la vectorización de las palabras. Esta matriz puede ser tratada de forma similar a una imagen y puede ser modelada por una CNN.
La ventaja principal que tienen las CNNs es su capacidad de mirar un grupo de palabras contiguas usando una ventana de contexto. Por ejemplo: se está haciendo un análisis de sentimiento y se obtiene la siguiente oración: “I like this movie very much!”. Para dar sentido a esta oración hay que analizar cada una de las palabras y los diferentes conjuntos que se forman a partir de las palabras contiguas. Las CNNs pueden hacer exactamente esto por definición de su arquitectura.

Como se muestra en la imagen, CNN utiliza una colección de capas de convolución y agrupación (pooling) para lograr esta representación condensada del texto, que luego se alimenta como entrada a una capa completamente conectada para aprender algunas tareas de NLP como la clasificación de texto.
- Transformers¶
Los Transformers son la última gran innovación en NLP. Los modelos de transformers modelan el contexto textual pero no de manera secuencial. Dada una palabra de input, prefiere mirar todas las palabras a su alrededor (lo que se conoce como autoatención (self-attention)) y representar cada palabra con respecto a su contexto. Por ejemplo, la palabra “banco” puede tener diferentes significados según el contexto en el que aparezca. Si el contexto habla de finanzas, entonces “banco” probablemente denota una institución financiera. Por otro lado, si el contexto menciona un río, entonces probablemente indica una orilla del río (river banks es orilla de río en inglés).
Los transformers pueden modelar dicho contexto y, por lo tanto, se han utilizado mucho en tareas de NLP debido a esta mayor capacidad de representación en comparación con otras redes profundas.
Últimamente, se han estado usando transformers que han sido alimentados por millones de datos para hacer transfer learning. Transfer learning es una técnica en inteligencia artificial que busca transferir el conocimiento adquirido por un modelo que resuelve un problema específico a otros problemas diferentes, y que están de cierta forma relacionados con el problema raíz. La idea en este caso es entrenar un transformer alimentado con muchos datos de forma no supervisada para que prediga una parte de una oración dado cierto contexto para que pueda codificar los matices de alto nivel del lenguaje en él. Generalmente, estos modelos son entrenados con más de 40Gb de datos textuales que son scrapeados desde la internet.
Un ejemplo de transformers robustos sería BERT (bidirectional encoder representations from transformers).

La figura muestra la arquitectura de BERT: Pre-entrenada por Google y creada para resolver tareas de Question Answering.
En la parte izquierda se aprecia un modelo pre-entrenado. Luego, este modelo se ajusta con precisión en las tareas posteriores de NLP, como la clasificación de texto, la extracción de entidades, la respuesta a preguntas, etc., como se muestra en el lado derecho. Debido a la gran cantidad de conocimientos formados previamente, BERT funciona de manera eficiente en la transferencia de conocimientos para tareas posteriores y logra el estado del arte para muchas de estas tareas.
La figura muestra el mecanismo de auto-atención (self-attention) en un transformer.
- Autoencoders¶
Un Autoencoder (codificador automático) es un tipo diferente de red que se usa principalmente para aprender la representación vectorial comprimida del input. Por ejemplo, si queremos representar un texto mediante un vector, ¿cuál es una buena forma de hacerlo? Podemos aprender una función de mapeo del texto de entrada al vector. Para que esta función de mapeo sea útil, “reconstruimos” la entrada a partir de la representación vectorial. Esta es una forma de aprendizaje no supervisado ya que no necesita labels etiquetadas por humanos para ello. Después del entrenamiento, recopilamos la representación vectorial, que sirve como codificación del texto de entrada como un vector denso. Los autoencoders generalmente se usan para crear representaciones de características necesarias para cualquier tarea posterior.

La figura muestra la arquitectura estándar de un Autoencoder.
En esta figura, la capa oculta brinda una representación comprimida de los datos de entrada, capturando la esencia, y la capa de salida (decoder) reconstruye la representación de entrada a partir de la representación comprimida. Si bien la arquitectura del autoencoder que se muestra no puede manejar propiedades específicas de datos secuenciales como el texto, algunas variaciones de estos, como los autoencoders LSTM, los abordan bien.